

The Power of the Incident Response Plan
Incident response is a key element of SOC and having the appropriate resources and procedures in place beforehand is a vital element to responding effectively to incidents. In this article I will be doing a high level overview of the incident response process and how it affects the SOC’s ability to handle problems.
Incident response is a topic I have learnt extensively about during my studies and actively participated in during the course of my job. At a senior level in support it’s not uncommon to be involved in the resolution or to be the one to identify the high severity.
Finally, while I want these articles to be as comprehensive as I can during the writing of this I realised to my dismay the sheet size this article would end up as if I gave it the full attention it deserved. This will therefore be an abbreviated version with perhaps future follow up articles exploring each area in more depth.
Section One – Incident Response in a Security Context
Incident response, at least in the broader IT sense is the process of handling high severity incidents which occur throughout an organisastion. In a traditional sense this could range from anything to a network outage to application downtime or something as simple as a locked workstation delaying the submittal of a critical bid. The incident is subjective to the organisation but the primary criteria is that it would either have a significant impact on the company’s operations, result in a financial penalty or both.
A prime example of this I stumbled onto recently during my work. I assisted a newly appointed directly with setup of their machine, however I noticed that despite being in the correct authorisation groups in AD the VPN denied access. Puzzled I took it away but heard of others complaining about the same issue, again for other starters. Realising an issue was present I reported the issue to incident management as the trend suggested that any new starters were unable to connect. While helping investigating we determined that there AD replication failure between domain controllers due to LDAP being blocked at the firewall. While this seems a small issue, in a company the size of the one I work for, the failure for AD to replicate would cause innumerable issues within a short space of time and was therefore good that it was resolved in a priority manner.
To continue however, redundancy is an important consideration for an organisation as the additional upkeep can be worth it when weighing against the reputational, financial and other costs that can occur through a high severity. Despite this however it is not always practical or possible to have these in place which is where the incident response team comes into account.
In a security context however Incident Response takes on another meaning. While the primary priority of Incident Response is to restore in Security it’s to prevent. Security Incident Response can be categorised into three broad categories:
- Security Event – An observable occurrence that relates to a security function (e.g. a detected port scan)
- An adverse event – An event that has negative consequences (e.g. malware infection, server crash, unauthorised access to files)
- A Security Incident – A imminent or occurring threat of CS policies such as AUP, avoidance of DLP, or malware infection such as a keylogger.
Section 2 – Incident Response Phases
The Computer security indident response team (CSIRT) are the team which are responsible for responding to security incidents. These are trained professionals and a company typically have a playbook created beforehand to manage and guide the response of the team. In this section I will cover the phases of a Security Incident and how the CSIRT may act.
Note that while NIST-800-61 is commonly the most frequently used and referred to, most of my primary learning comes from COMPTIA which explains the incident response process differently. The below will be a mix of the two based on the way this best makes sense to me.
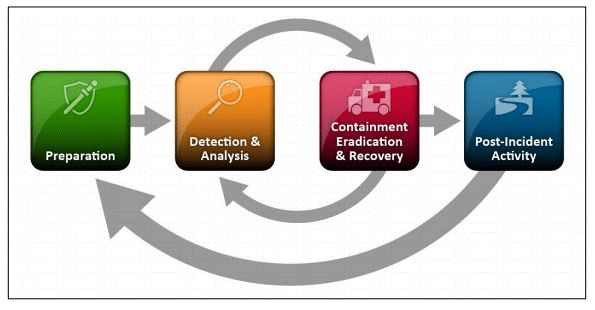
Stage One – Preparation
Preperation, while not actively involved in stopping an incident itself is a key and vital part of the process. The preparation stage of CSIRT requires many tools, policies, resources and guides to be made available to the team in order to be able to effectively combat security incidents.
The perhaps most important part of preparation is having the correct personel. The correct staff need to be hired and further learning and training provided to allow them to effectively deal with incidents. Examples of what should be provided to team members include:
- Digital Forensic Workstations
- Backup devices
- Spare laptops for collection and analysis purposes
- Correct software for forensic, packet capturing, analysis, detection, reporting and alerting.
In addition to this policies should be drawn up, playbooks created and organisations can perform live and tabletop exercises to familiarise team members on how to respond in specific situations.
There are many further examples of what could be provided but I believe the above provides sufficient insight to the importance of the preparation stage entails.
Stage 2 – Detection & Identification
This area is where I begin to differ slightly from NIST but only in semantics. The detection and identification phrase a complex one but is again vitally important to the process.
An organisation requires detection capabilities to even be aware that a security incident is taking place. A bad actor or even inside threat is not going to alert the relevant teams that they are circumventing policy and as such there needs to be monitoring, detection and alerts in place to allow the CSIRT to take action. For this methods such as port taps, IDS, IPS, log management and collation and of course the famous SIEM all come into play here to detect the breach and relay it to the CSIRT’s attention for action.
While the above covers in a limited fashion the internal tools used to detect ongoing or previous security threats that have already affected a system, there are other types of security incidents which can be indicated by other sources of intelligence. Threat feeds and corporate bulletins for example can alert organisations of insecure software or physical vulnerabilities which can be exploited by a bad actor and therefore need to be addressed to mitigate that risk.
Identification on the other hand is the process of interpreting the incoming data to determine whether an incidents actually occurred and if so work out the cause and potential resolution to the incident. Afterall false positives can be reported due to misconfiguration or simple user error.
An example of this are the random checks which are performed by myself each time I employ admin. The unintended access to systems and tools often triggers alerts which I then would need to backup with a legitimate business reason to protect the organisation both from a stolen identity or against bad actors.
Containment
This is where we begin to differ slightly from NIST but only in the sense that Containment and Eradication are broken into two distinct categories. I would assume this makes it easier to measure understanding in the COMPTIA tests but to me at least the distinction is there.
The containment phase of the Security Incident response plan is to mitigate the impact of the security incident. Containment can mean an awful lot of things depending on the scenario but some examples include:
- Segmenting or air-gapping a suspect workstation or server
- Adding firewall rules in the event of access to a malicious URL or unusual network activity
- Revoking access from individuals thought to be involved with a security breach
Picking the correct containment method can be a complex decision. A lack of data can cause a issues with the scope of containment. In addition the level of containment can be difficult to determine. Quarantine a single or an entire set of load balancing server running an application for example.
Eradication
Once the threat has been mitigated then the work to eradicate the threat begins. As with containment this can mean a number of things based on the scenario but perhaps the most commonly thought of is determining and removing malware from a system. Still examples of this are:
- Reimaging of affected machines or systems
- Patching vulnerabilities used
- Application reconfiguration to remove vulnerability
After each attempt tried the CSIRT should review the issue to determine if the threat has been successfully eradicated. If not then the plan loops back round to the analysis stage to determine if any detection failure occurred or if the current action has failed to resolve the threat.
In the event of malicious action, attempts should be made to identify the attacker, however the priority of this should not be prioritised over bringing back full functionality back at the earliest possibility.
Recovery
The recovery stage revolves around recovering any harm or bringing systems back up which were taken offline during the containment or eradication process. Essentially this boils down to bringing everything back to full functionality.
Examples of this could be:
- Restoring from backups
- Re-imaging infected systems with updated patches
- Damage control around exfiltrated data
An important consideration here is the MTTR (Mean time to Restore) which dictates the speed at which affected systems can be brought back online.
Lessons Learnt
The lessons learnt section of the incident response plan act as the after action report which highlights a number of things:
- What caused the issue
- What the resolution was
- What can be done to prevent these issues in the future
- What went well and vice versa during the incident response process
- How the staff and related parties performed
- Whether additional resources are required for CSIRT team to better respond in the future
- Whether the playbook was correctly followed
From the above you can see similarities to the preparation stage of the Incident Response process. Lessons learnt from this report are fed back to the preparation stage and are (hopefully) integrated into the future to better combat future incidents.
Special Consideration
While not directly related to the above phases there are a number of key considerations that should be accounted for during the process.
- Documentary Evidence should be collected at all times. This is pivotal due to the potential for legal action in the case of customer, employee or other stakeholder data breach or damage.
Conclusion
Responding to an incidents can take tremendous knowledge and level headed thinking to perform correctly. Luckily following the incident response plan can help simplify this process and more importantly find a way for organisations to standardise an approach based on an internationally approved concept, reducing beurocracy and promoting effectiveness.
Finally, while this article has become longer than I do plan to continue exploring this topic in later articles. The containment stage especially piqued my interest as this to me as something that would be useful to know in depth.
Sources
CYSA+ Study Guide CS0-002 by Mike Chappel & David Seidl
SP 800-61 Rev. 2, Computer Security Incident Handling Guide | CSRC (nist.gov)
https://cynet.com/incident-response/nist-incident/response/
https://heimdalsecurity.com/blog/what-is-eradication-in-cybersecurity/
https://www.titanfile.com/blog/phases-of-incident-response/
https://www.blog.rsisecurity.com/the-6-phases-of-the-incident-recovery-process/